

Engineering Challenges of Running Generative AI at Scale for Millions of Concurrent Players
We spent decades mastering the art of shipping video games with static assets. We built global empires on the back of Content Delivery Networks, becoming ruthlessly efficient at pushing textures, meshes, and audio to the edge of the network. We solved for a world where the payload was pre-baked, predictable, and known.
That world is gone.
The evolution here isn’t simply about using AI to generate content. We’re building AI directly into the beating heart of the live game experience. We’re not just shipping assets anymore. We’re shipping intelligence. Dynamic NPCs, emergent narratives, AI Game Directors orchestrating unique player journeys. These next-generation game mechanics aren’t files to be cached. They are ephemeral thoughts, synthesized in real-time by voracious, compute-hungry models.
And this creates a titanic collision. The brutal, low-latency demands of a global, live-service game are slamming directly into the chaotic, economically terrifying reality of generative AI at scale. The biggest threat to your AI-native game isn’t a competitor or a bad model. It’s an architecture that will suffocate under the weight of its own intelligence. As Google Cloud highlights, we’re entering the era of “living games” that adapt and grow with gen AI, but scaling that to millions means rethinking everything from the ground up.
The Compute Crunch

Generative AI is a resource hog like nothing we’ve seen in traditional game dev. We’re dealing with models that crave specialized hardware (GPUs by the truckload, TPUs if you’re fancy), and they don’t play nice with your standard server racks. Datacenters are buckling under the strain because these workloads are memory-bound, not just compute-heavy, leading to sluggish token generation that kills real-time vibes. Imagine trying to serve personalized dialogue for an NPC in a massive multiplayer session: each inference call chews through tokens, and with millions of players hammering the system simultaneously, you’re looking at clusters of 100,000+ GPUs just to keep up. The power draw alone is apocalyptic, with racks sucking down 100kW or more, forcing redesigns with liquid cooling and proximity to power plants to avoid blackouts.
This isn’t hyperbole.
At Electronic Arts, they’re advancing AI/ML infra to scale teams, applications, and data processing across hybrid environments, running into the same bottlenecks we all face. Roblox, powering inference for 79 million daily active users, runs 250+ ML pipelines across hybrid clouds and data centers, blending CPUs and thousands of GPUs.
The challenge?
Fragmented setups lead to waste and teams building siloed mini-platforms that don’t scale. We’ve learned the hard way that without unified orchestration, you’re overprovisioning hardware, spiking costs, and still hitting bottlenecks during peak hours when everyone’s raiding the same boss or chatting up AI companions.
Latency & Cost of Compute

Let’s be totally honest. The dazzling demos of AI-powered gameplay are a siren song, luring studios toward a rocky shore of operational disaster. The existential engineering challenge isn’t conceiving of a brilliant AI mechanic. It’s delivering it to millions of concurrent players without shattering immersion or incinerating your budget.
This is a war fought on two fronts.
First, there’s latency. The speed of light is a harsh mistress. When a player in Berlin is waiting for an AI-driven NPC to respond, and the inference is happening on a GPU cluster in Virginia, the conversational gap doesn’t just feel slow, it feels dead. It shatters the illusion. For the interactive, AI-driven mechanics that represent the future of this industry, sub-100-millisecond latency isn’t a luxury. This is the fundamental price of admission. Solutions like Gcore’s ultra-low-latency CDN aim for sub-50ms inference in most regions, but even that requires edge-optimized setups to avoid the Bermuda Triangle of cost, latency, and relevance.
Second, and more insidiously, there’s cost. The eye-watering expense of training foundational models is a rounding error compared to the persistent, operational bleed of inference at scale. This is the economic guillotine hanging over every AI-native project. Every token generated, every GPU cycle consumed, every second of every day, drains the lifeblood of the project. NVIDIA’s benchmarks show that balancing cost per token with performance is key, but in multiplayer games, success amplifies the pain: one studio saw API costs rocket from $5K to $250K in weeks as players piled in. Datacenters are projecting $200B+ spends in 2025 just to keep pace, with power and cooling alone jacking up TCO.
You Can’t Cache a Thought

The old playbook is useless here. Our beloved CDNs, the champions of delivering static content, are the wrong tool for this new reality. Why? Because you can’t pre-cache what doesn’t exist until the instant it’s needed.
Generative inference is a dynamic, context-dependent act of creation. The AI’s response is unique to the player, the moment, and the evolving state of the game. A CDN is built to replicate the known. We now have to deliver the unknown. Its edge nodes are lean, mean delivery machines optimized for storage and bandwidth, not the raw computational muscle required for model inference. Asking a CDN to run a generative model is like asking a Formula 1 car to haul freight. As Inworld notes at GDC 2025, scalability is the biggest hurdle for integrating AI into games, with off-the-shelf plugins failing at production scale.
This architectural mismatch forces us back to the drawing board. We need a new kind of stack, one designed from the ground up to manage the schizophrenic demands of performance, cost, and scale.
Taming Orchestration Chaos

Orchestrating this mess is where engineering dreams go to die. You’re juggling multi-agent systems for living worlds, hardware fragmentation across devices (from beastly RTX cards to mid-tier mobiles), and persistent state for coherent narratives spanning sessions. Traditional game servers? Laughable. You need frameworks like Ray for fault-tolerant, parallel processing, or Kubernetes clusters with dedicated GPU pools to flex between batch asset gen and real-time inference.
Control is key: AI agents must stay on-brand, remembering past interactions without hallucinating your lore into oblivion. Solutions like custom ML optimization and vector databases for embeddings help, but scaling to millions means observability overload (monitoring GPU util, token spend, anomalies) with tools like Prometheus baked in. Roblox’s vector DB enables fast lookups for multimodal search, but it took a ground-truth team to standardize pipelines. The goal? Empower devs to ship fast without fighting the infra.
Building the New Stack
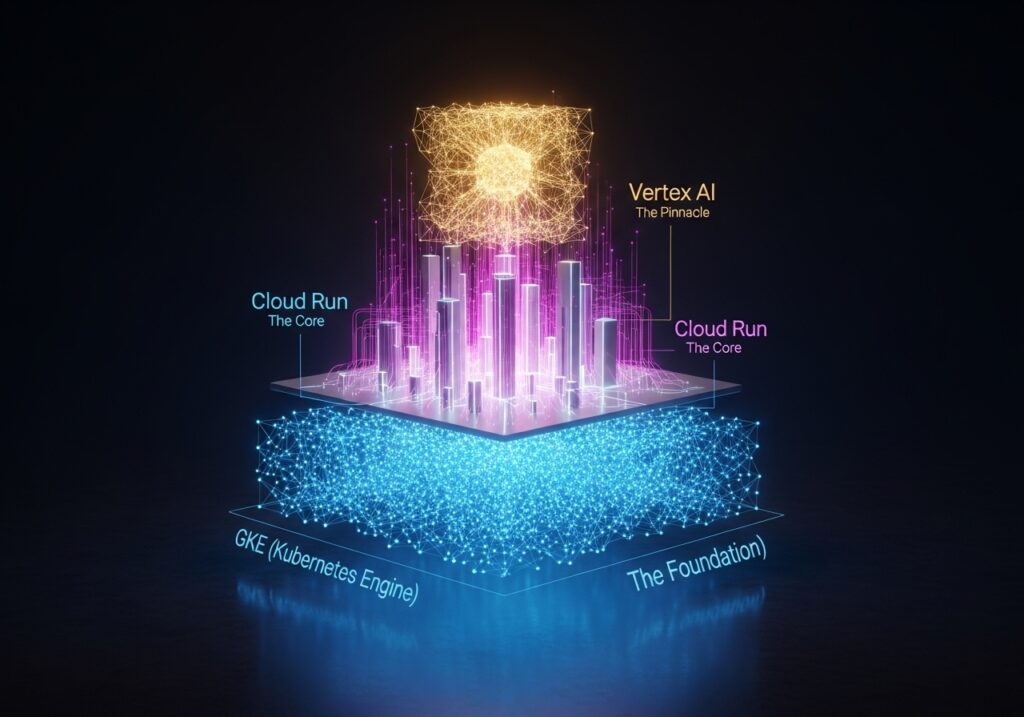
There is no silver bullet. The answer isn’t simply racking up more H100s. Winning requires a sophisticated, multi-tiered approach, adhering to the philosophy of using the right tool for the specific job, all orchestrated to balance the twin demons of latency and cost.
For the core, heavy-duty work, including foundational AI platform development, complex training jobs, or large-batch inference, we need maximum control. This is the realm of platforms like Google Kubernetes Engine (GKE). It’s the heavy-duty toolkit that lets us manage dedicated GPU node pools and deploy complex, containerized AI pipelines with performance predictability. It’s the foundational bedrock.
But not every AI service needs that level of intricate control. For many of our API endpoints, like powering narrative generation or specific in-game features, we need agility. This is where a service like Google Cloud Run becomes our workhorse. It lets us deploy containerized AI services with serverless ease but crucially overcomes the cold-start problem that kills latency. By keeping a minimum number of instances warm, we ensure the AI is always ready to think. It’s the perfect alignment for our “ship fast, learn faster” culture.
For pure, high-throughput model serving, purpose-built solutions like Vertex AI Endpoints are often the cleanest answer. They are optimized out-of-the-box for low-latency inference, abstracting away the underlying hardware and plugging directly into the broader MLOps ecosystem.
This isn’t about picking a single cloud service. It’s about building an intelligent system where workloads are routed to the most efficient and cost-effective layer of the stack, as seen in Omdia’s 2025 report on cloud platforms driving game dev trends.
The New Economic Reality

This architectural discipline is driven by a single, non-negotiable truth: cost is a design constraint. We are moving past the era where training costs dominated the conversation. The strategic battleground for the next decade is inference economics.
The winning strategy will be a hybrid one. It involves creating model cascades, using cheaper, faster models for 90% of tasks while reserving the expensive, powerful models for moments of complex reasoning. It means a relentless focus on model optimization, quantization, pruning, and distillation are no longer niche techniques but survival skills. NVIDIA’s ebook on balancing cost, latency, and performance underscores this for inference platforms.
The companies that thrive will be those that can answer a simple question: What is the total cost of ownership per delivered AI task? Those who can’t will build incredible technology that is financially unsustainable, especially in live service games where ongoing infra costs skyrocket with player retention.
Deploying Intelligence

Ultimately, even the most efficient centralized stack will hit the wall imposed by the speed of light. The true endgame, the solution to the global latency problem, is building a new kind of delivery network: a distributed, multi-tiered architecture for intelligence itself.
This is the next grand challenge. It’s a vision that blends powerful regional compute hubs, lighter-weight models running on more conventional edge infrastructure, and even on-device AI for instantaneous feedback. This isn’t a simple network, but a globally orchestrated intelligence, with a sophisticated routing layer making real-time decisions on where and how to process every single player interaction based on latency, cost, and complexity. As esports broadcasters are discovering, leveraging cloud and edge infra for global scaling is essential for low-latency content.
The CDN solved for content. Now, we must solve for intelligence.
The Path to Victory

The engineering challenges of scalable AI infra for live games aren’t optional. These are the gatekeepers to a successful AI-native future. We’re talking hybrid clouds, edge intelligence, cost-obsessed architecture, and orchestration that turns chaos into velocity. Companies like Roblox and EA are proving it’s possible, shipping for millions without imploding. But this isn’t a set-it-and-forget-it deal. This will be an ongoing battle against evolving models, spiking demands, and the sheer computational physics of scale.
If you’re building live games where gen AI is the heartbeat, infra is your secret weapon. Foster AI fluency across teams, shatter silos, and execute with blistering speed. The arms race is here. You can either lead it, or get left in the dust.